
YomiToku에서 만화 OCR 사용
1. YomiToku
YomiToku 는 로컬 서버에서 실행 가능하며 일본어 문서에 특화된 OCR 및 문서 이미지 분석을 수행하는 Python 패키지입니다.
https://note.com/kotaro_kinoshita/n/n70df91659afc
日本語に特化したOCR、文書画像解析Pythonパッケージ「YomiToku」を公開しました|Kotaro.Kinoshita
はじめに 最近、LLMへのRAGを用いた文書データの連携等を目的に海外を中心にOCRや文書画像解析技術に関連する新しいサービスが活発にリリースされています。 しかし、その多くは日本語を
note.com
일본어에 특화된 OCR, 문서 이미지 해석 Python 패키지 「YomiToku」를 공개했습니다. YomiToku는 PDF 및 카메라로 촬영한 문서 이미지를 분석하기 위한 Python 패키지입니다.
(추가내용)
일본어 => 한국어 번여을 통하여 응용범위가 있을 것으로 생가됩니다.
2. Google Colab에서 실행
'Google Colab'에서 수행하는 단계는 다음과 같습니다.
(1) 패키지 설치.
# 패키지 설치
!pip install yomitoku
(2) 가장 왼쪽의 폴더 아이콘으로 파일 목록을 열고 " sample.png "를 업로드합니다.
・sample.png

(3) OCR 실행.
# OCR
!yomitoku sample.png -f md -o results -v --figure
·${path_data}
: 해석 대상의 이미지가 포함된 디렉토리나 이미지 파일의 경로를 직접 지정해 주세요. 디렉토리를 대상으로 한 경우는 디렉토리의 서브 디렉토리내의 이미지도 포함해 처리를 실행. -f ,
--format
: 출력 형식의 파일 형식을 지정 . 출력처의 디렉토리명을 지정. 존재하지 않는 경우는 신규로 작성 됩니다 . 를 지정합니다. gpu 를 사용할 수 없는 경우는 cpu 로 추론이 실행 . 이미지의 개행 위치를 무시하고, 단락내의 문장을 연결해 돌려 준다 . 내보내기 .--- figure : 감지 된 그림, 이미지를 출력 파일로 내보내기 (html 및 markdown 전용)
" results" 폴더 아래에 세 개의 파일이 출력됩니다.
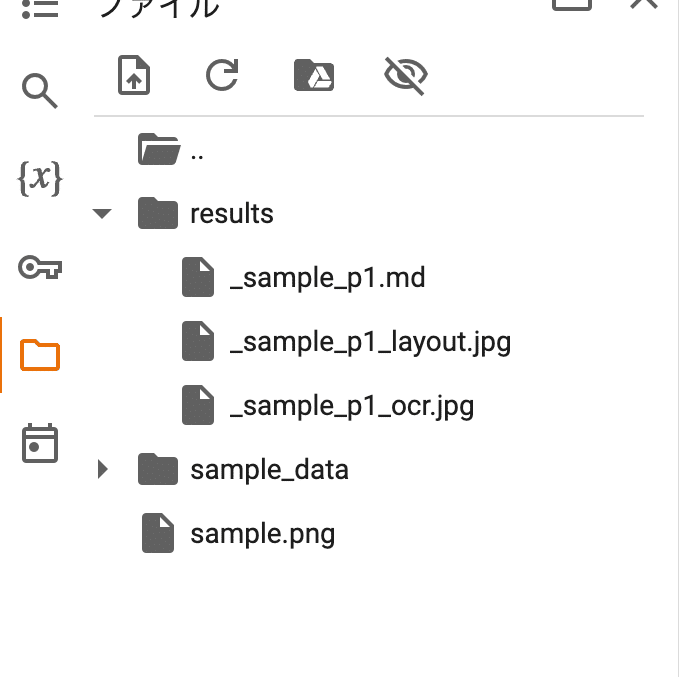
· _sample_p1_layout.jpg

・sample_p1_ocr.jpg

· _sample_p1.md
あう〜
ファイルサイズ<br>ぜんぜん小さく<br>ならないよ
どうしよう<br>i坊
ファイルサイズ<br>小さくするには<br>コツがあるからな
クラスや<br>メソッドの数を<br>少なくしたり
1つの変数を<br>使い回したり
プリプロセッサ<br>を使ったり
逆アセンブル<br>して無駄ないか<br>チェックしたり
さすがi坊<br>その方法で<br>小さくして<br>おいてね
300K
한국어 번역
아~
파일 크기 <br> 전혀 작지 않습니다.
어떻게하자<br>i보
파일 크기 <br>작게 만들려면 요령이 있기 때문에
클래스 및 <br>메소드의 수를 줄이거나
하나의 변수를 사용하여 돌리거나
전처리기<br>를 사용하거나
디스어셈블리하고 낭비하지 않는지 확인하십시오.
과연 ibo <br>그런 식으로 작게 만들어주세요.
300K
(추가 내용)
다음단계는
원 일본 글자 위치에 한국 번역글을 치환하여 변형 가능하게끔 할 수 있는 방법이 있을지
계속 찾아 봐야 겠네요 ^^