Jetson Nano, AI 컴퓨팅을 모든 사람들에게 제공

엔비디아는 2019 년 엔비디아 GPU 기술 컨퍼런스 (GTC)에서 제트온 나노 개발자 킷 (Jetson Nano Developer Kit) 을 발표했다. 엔비디아 GPU 기술 컨퍼런스 (GTC)는 임베디드 디자이너, 연구원 및 DIY 제조업체가 사용할 수있는 99 달러짜리 컴퓨터로, 현대 AI의 강력한 기능을 소형의 사용하기 쉬운 플랫폼에 제공한다. 완전한 소프트웨어 프로그램 가능성. Jetson Nano는 쿼드 코어 64 비트 ARM CPU와 128 코어 통합 NVIDIA GPU를 통해 472 GFLOPS의 컴퓨팅 성능을 제공합니다. 그림 1과 같이 5W / 10W 전력 모드와 5V DC 입력을 갖춘 효율적인 저전력 패키지에 4GB LPDDR4 메모리가 포함되어 있습니다.
새롭게 출시 된 JetPack 4.2 SDK 는 가속 그래픽, NVIDIA CUDA Toolkit 10.0 지원 및 cuDNN 7.3 및 TensorRT 5와 같은 라이브러리를 지원하는 Ubuntu 18.04를 기반으로하는 Jetson Nano의 완벽한 데스크탑 Linux 환경을 제공합니다. SDK에는 또한 네이티브 OpenCV 및 ROS와 같은 컴퓨터 비전 및 로봇 개발을위한 프레임 워크와 함께 TensorFlow, PyTorch, Caffe, Keras 및 MXNet과 같은 오픈 소스 Machine Learning (ML) 프레임 워크를 제공합니다.
이러한 프레임 워크 및 NVIDIA의 선도적 인 AI 플랫폼과의 완전한 호환성으로 인해 AI 기반의 추론 워크로드를 Jetson에보다 쉽게 배포 할 수 있습니다. Jetson Nano는 다양한 복합 신경 네트워크 (DNN) 모델에 실시간 컴퓨터 비전 및 추론 기능을 제공합니다. 이러한 기능을 통해 다중 센서 자율 로봇, 인텔리전트 에지 분석 기능을 갖춘 IoT 장치 및 고급 AI 시스템을 사용할 수 있습니다. ML 프레임 워크를 사용하여 Jetson Nano에 로컬로 네트워크를 재 교육하는 경우에도 전송 학습이 가능합니다.
Jetson Nano Developer Kit는 80x100mm 크기의 공간에 적합하며 4 개의 고속 USB 3.0 포트, MIPI CSI-2 카메라 커넥터, HDMI 2.0 및 DisplayPort 1.3, 기가비트 이더넷, M.2 Key-E 모듈, MicroSD 카드 슬롯, 및 40 핀 GPIO 헤더. 포트 및 GPIO 헤더는 NVIDIA가 GitHub에서 공개 소스 로 사용하는 3D 인쇄 가능한 심층 학습 JetBot 과 같이 널리 사용되는 다양한 주변 장치, 센서 및 즉시 사용할 수있는 프로젝트와 함께 즉시 사용할 수 있습니다.
devkit은 SD 카드 어댑터가있는 모든 PC에서 포맷 및 이미지 처리가 가능한 이동식 MicroSD 카드로 부팅됩니다. devkit은 마이크로 USB 포트 또는 5V DC 배럴 잭 어댑터를 통해 편리하게 전원을 공급받을 수 있습니다. 카메라 커넥터는 Jetson 생태계 파트너가 제공하는 8MP IMX219 기반 모듈을 포함하여 저렴한 MIPI CSI 센서와 호환됩니다. 또한 JetPack에서 드라이버 지원을 포함하는 Raspberry Pi Camera Module v2도 지원됩니다. 표 1은 주요 사양을 보여줍니다.
devkit은 그림 2와 같이 260 핀 SODIMM 스타일 SoM (System-on-Module)을 기반으로 설계되었습니다. SoM에는 프로세서, 메모리 및 전원 관리 회로가 포함되어 있습니다. Jetson Nano 컴퓨팅 모듈은 45x70mm이며 2019 년 6 월부터 임베디드 디자이너가 프로덕션 시스템에 통합하기 위해 $ 1000 (단위 수량 기준)에 129 달러에 출하 할 예정입니다. 생산 컴퓨팅 모듈에는 PCIe Gen2 x4 / x2 / x1, MIPI DSI, 추가 GPIO, 최대 3 개의 x4 카메라 또는 최대 4 개의 카메라 연결을위한 12 레인의 MIPI CSI-2를 갖춘 16GB eMMC 온보드 스토리지 및 향상된 I / O가 포함됩니다. x4 / x2 구성. Jetson의 통합 메모리 서브 시스템은 CPU, GPU 및 멀티미디어 엔진간에 공유되며 능률적 인 ZeroCopy 센서 인제 스트와 효율적인 프로세싱 파이프 라인을 제공합니다.

심화 학습 추론 벤치 마크
Jetson Nano는 TensorFlow, PyTorch, Caffe / Caffe2, Keras, MXNet 등과 같은 인기있는 ML 프레임 워크의 완전한 기본 버전을 포함하여 다양한 고급 네트워크를 실행할 수 있습니다. 이러한 네트워크는 이미지 인식, 객체 감지 및 로컬라이제이션, 포즈 추정, 의미 론적 세분화, 비디오 향상 및 지능형 분석과 같은 강력한 기능을 구현하여 자율 기계 및 복잡한 AI 시스템을 구축하는 데 사용할 수 있습니다.
그림 3은 온라인에서 사용 가능한 인기 모델 전반의 추론 벤치 마크 결과를 보여줍니다. 추론 에서는 JetPack 4.2에 포함 된 NVIDIA의 TensorRT 가속기 라이브러리를 사용하여 배치 크기 1 및 FP16 정밀도를 사용했습니다 . Jetson Nano는 여러 시나리오에서 실시간 성능을 달성하며 여러 고화질 비디오 스트림을 처리 할 수 있습니다.
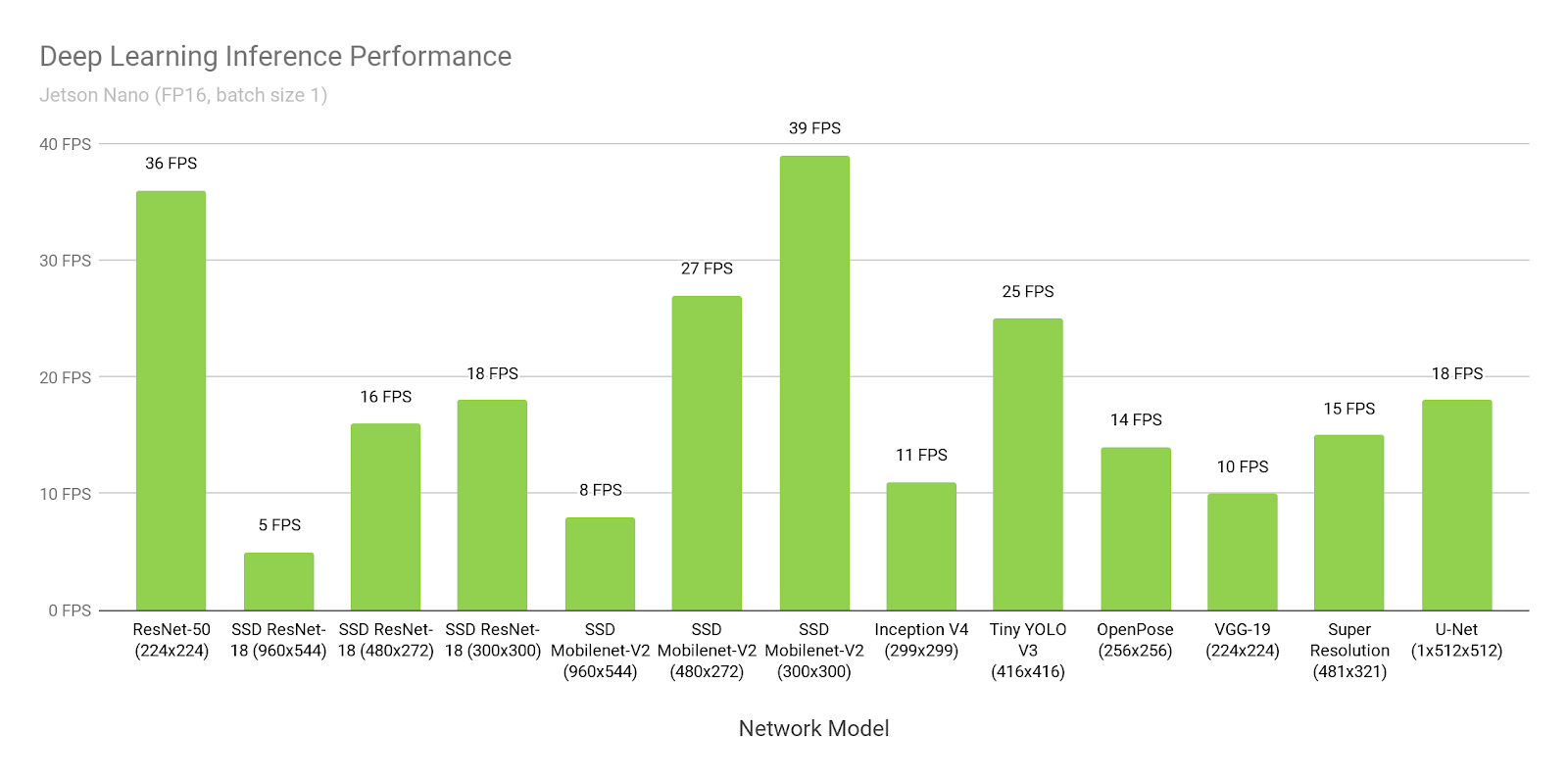
표 2는 Raspberry Pi 3, Intel Neural Compute Stick 2 및 Google Edge TPU Coral Dev Board와 같은 다른 플랫폼의 성능을 포함한 전체 결과를 제공합니다.
DNR (실행되지 않음) 결과는 제한된 메모리 용량, 지원되지 않는 네트워크 계층 또는 하드웨어 / 소프트웨어 제한으로 인해 자주 발생합니다. 고정 기능 신경망 가속기는 하드웨어에서 지원되는 전용 계층 작업을 통해 상대적으로 좁은 사용 사례 집합을 지원하며 중요한 데이터 전송 불이익을 피하기 위해 제한된 온칩 캐시에 네트워크의 가중치 및 활성화가 필요합니다. 하드웨어에서 지원되지 않는 레이어를 실행하기 위해 호스트 CPU에서 폴백 할 수 있으며 프레임 워크의 하위 집합 (예 : TFLite)을 지원하는 모델 컴파일러에 의존 할 수 있습니다.
Jetson Nano의 유연한 소프트웨어와 전체 프레임 워크 지원, 메모리 용량 및 통합 메모리 하위 시스템을 통해 다중 센서 스트림에서 가변 배치 크기를 동시에 지원하는 등 다양한 네트워크를 풀 HD 해상도까지 실행할 수 있습니다. 이러한 벤치 마크는 널리 사용되는 네트워크의 샘플을 나타내지 만 사용자는 가속화 된 성능으로 Jetson Nano에 다양한 모델 및 사용자 지정 아키텍처를 배포 할 수 있습니다. 그리고 Jetson Nano는 DNN 추론에만 국한되지 않습니다. CUDA 아키텍처는 사용자 정의 쿠다 커널과 함께 FFT, BLAS 및 LAPACK 연산을 포함한 알고리즘을 사용하여 컴퓨터 비전 및 디지털 신호 처리 (DSP)에 활용 될 수 있습니다.
다중 스트림 비디오 분석
Jetson Nano는 최대 8 개의 HD 풀 모션 비디오 스트림을 실시간으로 처리하며 NVR (Network Video Recorders), 스마트 카메라 및 IoT 게이트웨이를위한 저전력 에지 인텔리전트 비디오 분석 플랫폼으로 배포 할 수 있습니다. NVIDIA의 DeepStream SDK 는 ZeroCopy 및 TensorRT를 사용하여 엔드 투 엔드 추론 파이프 라인을 최적화하여 에지 및 사내 구축 형 서버에서 최상의 성능을 제공합니다. 아래의 비디오는 Jetson Nano가 8 개의 1080p30 스트림에서 동시에 전체 해상도로 실행되는 ResNet 기반 모델과 초당 500 메가 픽셀 (MP / s)의 처리량으로 오브젝트 감지를 수행함을 보여줍니다.
Jetson Nano에서 실행되는 DeepStream 응용 프로그램으로 ResNet 기반
객체 감지기가 8 개의 독립적 인 1080p30 비디오 스트림에서 동시에 실행됩니다.
그림 4의 블록 다이어그램은 Jetson Nano를 사용하여 심층 학습 분석을 통해 기가비트 이더넷을 통해 최대 8 개의 디지털 스트림을 처리하고 처리하는 NVR 아키텍처의 예를 보여줍니다. 이 시스템은 H.264 / H.265의 500 MP / s를 디코딩하고 H.264 / H.265 비디오의 250 MP / s를 인 코드 할 수 있습니다.

Jetson Nano에 대한 DeepStream SDK 지원은 Q2 2019 릴리스 용으로 계획되어 있습니다. 곧 출시 될 릴리스에 대한 알림을 받으려면 DeepStream 개발자 프로그램 에 가입하십시오 .
JetBot
그림 5에 표시된 NVIDIA JetBot 은 250 달러 이하의 AI 기반 심층 학습 로봇을 구축하기위한 모든 소프트웨어 및 하드웨어 계획을 제공하는 새로운 오픈 소스 자율 로봇 키트입니다. 하드웨어 재료에는 Jetson Nano, IMX219 8MP 카메라, 3D 인쇄 가능한 섀시, 배터리 팩, 모터, I2C 모터 드라이버 및 액세서리가 포함됩니다.

이 프로젝트는 Jupyter 노트북을 통해 모터 제어를위한 Python 코드를 작성하는 방법, 장애물을 감지하도록 JetBot을 교육하는 방법, 사람과 가재 도구와 같은 물건을 따라가는 방법, JetBot을 훈련시켜 바닥 주위의 경로를 추적하는 방법에 대해 쉽게 배울 수있는 예제를 제공합니다. 코드를 확장하고 AI 프레임 워크를 사용하여 JetBot의 새로운 기능을 만들 수 있습니다.
또한 JetBot 용 ROS 노드 가있어 ROS 기반 응용 프로그램과 SLAM 및 고급 경로 계획과 같은 기능을 통합하려는 사람들을 위해 ROS Melodic을 지원합니다. JetBot 용 ROS 노드가 포함 된 GitHub 저장소에는 Gazebo 3D 로봇 시뮬레이터 모델이 포함되어있어 로봇에 배치되기 전에 가상 환경에서 새로운 AI 동작을 개발하고 테스트 할 수 있습니다. Gazebo 시뮬레이터는 합성 카메라 데이터를 생성하고 Jetson Nano에서도 실행됩니다.
안녕 AI 월드
안녕 AI World 는 Jetson을 사용하고 인공 지능의 힘을 경험할 수있는 좋은 방법을 제공합니다. 몇 시간 만에 JetPack SDK 및 NVIDIA TensorRT가 포함 된 Jetson Nano 개발자 키트에서 실시간 이미지 분류 및 객체 감지 (사전 교육 된 모델 사용)를위한 일련의 심층 학습 추론 데모를 실행할 수 있습니다. 튜토리얼은 컴퓨터 비전과 관련된 네트워크에 중점을두고 라이브 카메라를 사용합니다. 또한 C ++에서 쉽게 이해할 수있는 인식 프로그램을 코딩 할 수 있습니다. 사용 가능한 심층 학습 ROS 노드 는 이러한 인식, 탐지 및 세분화 추론 기능을 ROS 와 통합합니다. 고급 로봇 시스템 및 플랫폼에 통합 할 수 있습니다. 이러한 실시간 추론 노드는 기존 ROS 응용 프로그램으로 쉽게 삭제할 수 있습니다. 그림 6에서는 몇 가지 예제를 중점적으로 설명합니다.

자신의 모델을 시험해보고자하는 개발자 는 이미지 분류, 객체 감지 및 전송 학습을 통한 의미 론적 세분화 모델의 재교육 및 사용자 정의를 다루는 " 2 일 간의 데모"자습서 를 따를 수 있습니다 . 전송 학습은 특정 데이터 세트의 모델 가중치를 미세 조정하고 모델을 처음부터 교육하지 않아도됩니다. 전송 학습은 NVIDIA 개별 GPU가 연결된 PC 또는 클라우드 인스턴스에서 가장 효율적으로 수행됩니다. 교육에는 추론보다 계산 자원과 시간이 더 필요하기 때문입니다.
그러나 Jetson Nano는 TensorFlow, PyTorch 및 Caffe와 같은 전체 교육 프레임 워크를 실행할 수 있기 때문에 다른 전용 교육 시스템에 액세스 할 수없는 사용자를위한 전송 학습으로 재 훈련 할 수 있으며 결과를 기다리는 데 더 오래 기다릴 수 있습니다. 표 3은 AlexNet 및 ResNet-18을 200,000 이미지에서 교육하기 위해 Jetson Nano를 사용하여 PyTorch를 사용한 2 일간의 데모 자습서로의 이전 학습 결과의 일부, 22.5GB 하위 이미지 그룹을 보여줍니다.
시간당 시간은 200K 이미지의 교육 데이터 세트를 완전히 통과하는 데 걸리는 시간입니다. 분류 네트워크는 사용 가능한 결과에 대해 2-5 개 에포크를 필요로 할 수 있으며, 최대 정확도에 도달 할 때까지 별도의 GPU 시스템에서 더 많은 에포크에 대해 생산 모델을 교육해야합니다. 그러나 Jetson Nano를 사용하면 네트워크를 밤새 다시 훈련시켜 저가형 플랫폼에서 심층 학습 및 AI를 실험 할 수 있습니다. 모든 사용자 정의 데이터 세트가 여기서 사용 된 22.5GB 예제만큼 클 수 없습니다. 따라서 이미지 / 초는 데이터 세트의 크기, 트레이닝 배치 크기 및 네트워크 복잡성을 기준으로 시간별 시간별로 Jetson Nano의 교육 실적을 나타냅니다. Jetson Nano에서도 교육 시간을 늘려 다른 모델을 재 훈련 할 수 있습니다.
모두를위한 AI
Jetson Nano의 컴퓨팅 성능, 컴팩트 풋 프린트 및 유연성으로 인해 AI 구동 장치 및 임베디드 시스템을 개발할 수있는 개발자에게 무한한 가능성이 제공됩니다. 오늘 Jetson Nano 개발자 키트를 99 달러에 시작하십시오.이 키트는 당사의 주요 글로벌 유통 업체를 통해 판매 되며 제조업체 채널, Seeed Studio 및 SparkFun 에서도 구입할 수 있습니다 . 임베디드 개발자 존 을 방문 하여 소프트웨어 및 문서를 다운로드하고 Jetson Nano에서 사용할 수있는 오픈 소스 프로젝트를 탐색하십시오 . Jetson DevTalk 포럼 의 커뮤니티에 가입 하여 프로젝트를 공유하십시오. 우리는 당신이 만드는 것을 보길 고대합니다!
https://devblogs.nvidia.com/jetson-nano-ai-computing/#disqus_thread
'기타제품 및 SW' 카테고리의 다른 글
| Google+ 계정 및 커뮤니티를 MeWe로 가져 오는 방법 (0) | 2019.03.20 |
|---|---|
| Taihe Gemini 휴대용 1080p 터치 스크린 모니터 미리보기 (0) | 2019.03.19 |
| NVIDIA, 99 달러에서 손바닥 크기의 AI 보드 "Jetson Nano" (0) | 2019.03.19 |
| Microsoft의 'All-Digital'Xbox One은 5 월에 출시 될 수 있습니다. (0) | 2019.03.06 |
| 4세대 마그네틱 자석 고속충전 케이블(5) - 마그네틱 케이블 개발 및 양산 관련 에필로그 (2) | 2019.01.30 |